Who you need to be
Cricket player, actor, man, women, young, old... So many possibilities, but does everyone have the same chance to be quoted?
Isn't it a pleasure to be listened to? The ability to make your voice heard is a privilege that few have. Sometimes you can have the feeling that only the loudest are listened to. We have analyzed the Quotebank dataset from 2015 to 2020, and from it, we extracted information about the speakers from Wikidata. First, let us see who are the most quoted speakers!
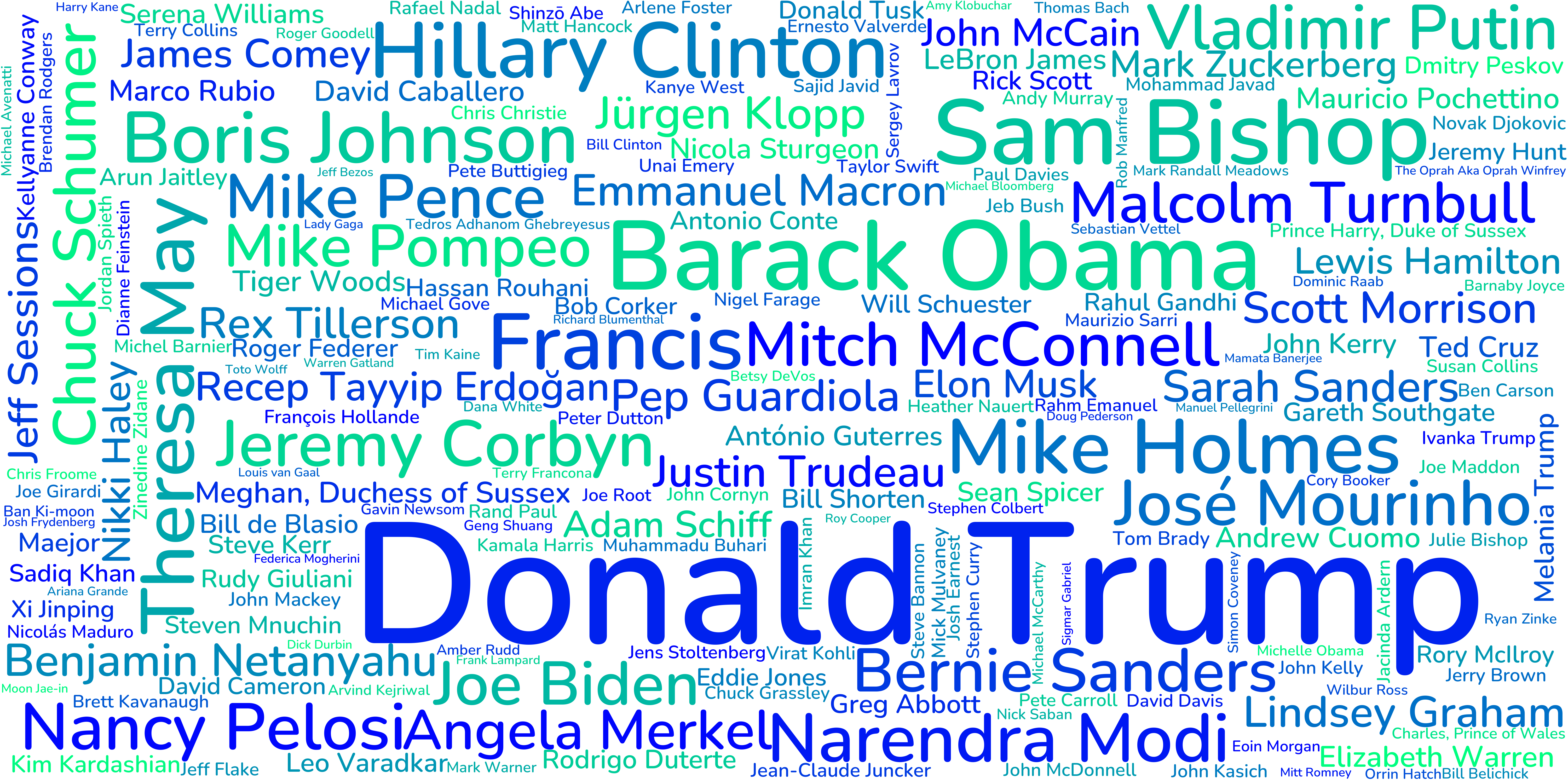
From this picture, we can see that we have a wide mixture of speakers. Unsurprisingly, the biggest names in the picture, and the most quoted speakers are American politicians and other world leaders, but we can also see a lot of sports personalities, business leaders, artists and influencers. Let us now take a deeper dive into the data...
1. Imbalance in number of quotations
As seen from the graph (log-scaled in the y-axis),
most quotes are made by a few people, and
most people have made a few quotes. In this dataset,
20% of the most quoted speakers have made 89% of the quotes! The
distribution of the number of quotes per speaker is a power law, and
interestingly also follows the
80/20 rule,
also known as the Pareto principle.
The Pareto principle was observed by the Italian economist Vilfredo
Pareto, who while at the University of Lausanne (!), showed that 80% of
the land in Italy was owned by 20% of the population. This distribution
has further been seen in other areas such as ~80% of wealth is owned by
20% of the population, ~80% of all end users generally use only 20% of a
software application's features, and ~80% of health care resources are
spent on 20 % of the patients. Now we find that 89% of quotes are made
by 20% of quoted speakers. Note however that the Pareto principle is not
a law like most other principles, but merely an observation of a phenomenon.
To answer the question who has a voice in the media?, we
want to focus on people that are quoted regularly. A person that has
only been quoted once does not really have "a voice in the media", and
therefore going forward in our analysis, we will only consider speakers
that have made more than 5 quotes.
2. Male-dominated quotations
When we break down the speakers by gender, we can see that males stand for ~77% of all quotations, females for ~22%, and other genders for a little over 1%. Even though the data presented have been combined over the years 2015-2020, we have not observed significant changes in the distribution of genders over these years.

3. Occupation distribution
Here we break down the speakers by gender and occupation. We can see that the overall most common occupation is politician, but when we break it down by gender we find that politician is actually not the most common occupation in any of the genders. We instead find that males lean towards sports, while women lean towards creative occupations such as actor, singer, and writer. To reduce the complexity of the data and to more easily compare the occupations, we decide on a fixed set of relevant occupation groups: politician, athlete, actor, lawyer, researcher, journalist, musician, and businessperson. We then use the lexical database Wordnet to calculate similarities between each occupation and each occupation group and add the occupation group as a new feature in the dataset.
4. Age and occupation group
Now, let's take a deeper dive into speakers' occupations. For the sake of conciseness, we consider the following three main occupation subgroups:
- Politicians
- Athletes, among which we count Association/American football players, basketball players, ice hockey players, cricketers, and all kinds of athletic competitors.
- Artists, consisting of actors, singers, musicians, painters, etc.
The analysis leads to the following insights:
- Male politician speakers are, on average, older than their female counterparts (65.1 vs 61.2). A one-sided t-test supports this observation with a confidence level of 0.99.
- As expected, athlete speakers are among the youngest in the dataset. Interestingly, older male athletes also have a voice in the media. Indeed, former athletes that became famous sports figures are often males due to the important imbalance in sports coverage across genders in the past link.
- Finally, the subgroup of artists is no exception to the rule: male speakers are again significantly older.
NB: the density peaks at 21 y.o. for both genders come from imprecise date of birth information provided by Wikidata.
To sum it up: especially for sport and art-related occupations, a female speaker has much better chances of being quoted while being young,
while men have an easier time getting quoted even when they become older.
5. Clustering
As we have seen in the plots before, the different variables can be combined in many ways if we want
to understand the data. On the other hand, manually finding the relevant combination of features is
complex to find, thus we wanted rather do this in an unsupervised manner to let the data talk by itself!
With that in mind, we performed clustering with K-means with the following variables: gender, age, number of quotes,
and occupation. With the elbow method, we decided that 3 was the best amount of clusters to divide the speakers in.
Let us see the distributions of the occupations and ages of the found clusters!
Cluster A
Cluster A is primarily composed of politicians, even though a huge proportion of it is made of art-related jobs, such as actor or singer. Counting more quotes than the other two clusters combined, it is also the oldest cluster with over 50% of it being over 60 years old. Indeed, known politicians are usually on the older side of the force...
Cluster B
Cluster B is composed similarly to cluster A, except that the most found occupation is actor instead of politician. It has less than half the number of quotes of cluster A, which may be explained by the fact this cluster is much more balanced in terms of age.
Cluster C
Cluster C could be renamed 50 shades of sports. Indeed, the majority of the cluster is composed of sport-related occupations, unlike the first two clusters. Also, it is the youngest group, which is in accordance with occupations in it. Indeed, athletes tend to be younger than politicians.
What you need to talk about
From art to politics, what do you need to talk about to be quoted in all the most famous newspapers!
Topics in the clusters
Using a topic classification method, we determined the most probable topic for each quote. Overall, the three most talked about subjects are sport, art, and economy & finance. As the QuoteBank dataset was formed by collecting quotes from newspapers, this repartition of topics is nothing but expected. Indeed, sports and culture specialized newspapers are far more known by the general public than scientific publications journal for example. However, pure political subjects are not as predominant as one could have thought. To be able to analyze further how each group of people choose their subject to be quoted, let us dig a level below and take interest in the clustering results.
Cluster A, politicians that don't talk about politics?
As seen in the overall analysis, and contrary to what could have been common sense,
politics is not the most talked about subject of the politicians' cluster!
One specific reason may be explaining this oddity in our results. We can assume that
the model has classified in the "Politics" topic only quotes
that are centered on purely political subjects such as elections or nomination of a member of government.
Therefore all the subjects about the impacts of politics on the economy or in healthcare for example will
be classified in their respective category. Hence, it is not surprising to notice that,
apart from the elephant in room art topic, the three main subjects are economy, finance,
and of course politics...
Now let's talk about the aforementioned elephant in the room, the Art topic.
Who could have expected that politicians are mainly interested in art? Well..., they may be not.
Indeed, let's not forget that cluster A is also populated by writers, singers, and actors, which are all deeply art-oriented
occupations.
Cluster B, artists and their things...
Now that we have had a better understanding of the first cluster, let's analyze the second one. Like cluster A, cluster B is also populated by actors writers, singers, and politicians, but this cluster has a younger age overall and also is much less quoted. Cluster B also contains much more artists than cluster A. All of these reasons may explain why, in this group, more than 50% of the quotes are classified as art. All the other topics results are tight together, around 7% for health, science and politics, and 15% for sports, economy and finance.
Cluster C, everything for the sport!
Cluster C is made of young, fiery sportsmen and sportswomen. And as we can see on the topic classification results for this cluster, the big bulk of the quotes ( just above 50%) is about... Sports! In terms of sheer numbers, that makes it up to 21 million quotes about sport, which is much higher than for the two other clusters. However, a non-negligible portion of the quotes was classified in Art and Politics. That may be explained that even if they are sportsperson, everyone is prone to talk about those subjects. Finally, we see that the Economy & Finance topic is one of the less quoted subjects for cluster C. This is surely because it is very unlikely that a sportsperson will be asked a question about those two subjects during an interview or even talk about this subject in a relevant manner on the fly. The same thing could be said for health, but the fact that sport is highly related to health, in general, may explain the small difference in percentage.
How you need to say it
Now that you know how you need to and what you need to talk about, wouldn't it be nice if we also reveal how you need to say it?
Topics... and their emotions
Choosing the perfect subject is not enough to be quoted. And always having the same tone either. As we'll see in the next visualization, there is an interaction between the subject and the emotion of the quotes that are existing in the QuoteBank dataset.
Politics, which emotion to convince?
Politics is the topic for which emotions are the most balanced, compared to the other considered topics. The most used emotion in political quotes is sadness. However, the neutral tone is also frequently used. Only joy seems not to be part of the political arsenal to be quoted. That can be explained by several reasons: first, according to Ivan Garibay in a paper published in May 2021, controversial information spreads faster than non-controversial information. And those information mainly rely on negative ones, which may explain why joy is the less quoted emotion for this topic. Also, the politics topic will include more informative quotes which will likely end up in the more tamed emotions categories such as calm, sad, or neutral. Therefore, if you want to talk about politics, do it softly, and don't be too joyful!
No one likes to lose.
Like politics, sports-related quotes use mainly neutral emotions and sadness. The neutral tone may be explained by the fact that a lot of the quotes in the dataset related to the sport are about scores of specific matches, which by nature are objective and neutral. An interesting thought to note is that the joy emotion is even less used in sports than in politics and is four times less used than anger. From this may assume that the person that is quoted about sports will likely have lost instead of won. Losers seem to be more quoted than winners... The moral of the story so far, being happy does not get you quoted.
Hello sadness my old friend...
As an artist or someone who is refined enough to talk about Arts with a capital A, mastering emotion is key. And it seems that the quotations about this subject are on the brighter side than for politics or sports. Indeed even though sadness is still the most quoted emotion for this topic, calm and especially joyful quotes are found at a higher rate.
Have you seen the economy?!
Contrary to the three other topics studied, economy has the highest rate of fear-classified quotes. This can be rooted in the fact that economy-related quotes can address subjects like mass dismissal or bankruptcy which will be treated with a fearful emotion. This correlation is also supported by the fact that neutral quotes represent the smallest portion of economy-related quotes, which can be explained by the similarity between calm and neutral emotions. Therefore some quotes may have been classified as calm instead of neutral. However, if we assume that the model predicts quite accurately the emotion, one could conclude that economy is a much more emotion-related field than the other three, which is surprising, especially compared to the art topic. If economy is what you want to talk about, fear-mongering or a calm tone seems to be the way to get quoted.
Conclusion
After this long analysis of who you should be, what you should talk about, and how you should talk about it, what have we learned?
Throughout our data story, we took a deep dive into speakers attributes and learned key insights about the loudest individuals:
- Males' speeches are predominant. However, if you are a female speaker willing to make your voice heard, you probably want to be as young as possible.
- Newspapers love to transmit politicians', athletes', and actors' thoughts, especially if they are talking about art, politics, sport, or even economy!
- Emotion in your speech is key! And making the appropriate choice according to what you want to talk about is an art... If you had to remember just one thing: never talk about politics or sports with joy, the media are not interested in that.
Have you understood what it takes to be quoted? (Re)-take your chance on our beautiful game and see how loud you are.
Our Team
As our work speaks for itself, we'll keep it short: here we are, the Quotebankers! This is the course project of Applied Data Analysis at EPFL in Fall 2021.

Benjamin Hansson
Our Deep Learning & HTML expertBenjamin Hansson is one of the best HTML experts you could find in the world. Conscientious, always wanting to do more, Mr. Hansson, or Mr.Handsome as call him in-house will solve any Tensorflow problem you may have, whichever the version of the package. Yes, he is that good.

Eliott Zemour
Our plotly & NLP expertEliott knows NLP better than Michael Phelps knows how to swim. When doing topic classification, emotion classification, or classification classification, Eliott is like a fish in the sea. At ease. Period. But on top of that, he can also produce the most visually pleasing plots you may see during your lifetime.

Matheus Bernat
Our clustering expertMatheus clusters and he does it perfectly. K-modes, K-means, every K-stuff you could think of. Don't know if you should leave your data unsupervised ? Matheus baby-sits your data until it is organized like Marie Kondo's house. To say that he can discover new ways of thinking about data is a euphemism.

Thomas Benchetrit
Our UI & NLP expert
Thomas has those gold fingers that turn lines of code into magical interactive user interfaces. He is this kind of jack-of-all-trade that can design NLP models, create an API, build a house and resolve world hunger in just a day.
PS: if you got a mediocre score at the QuoteGame, hate the player, not the game.
Appendix
Datasets used
- Quotebank dataset The Quotebank dataset contains 178 million speaker-attributed attributed quotations collected from 162 million English news articles published between 2008 and 2020. The dataset is divided into phases A-E; in this project, only the phase E part (2015-2020) of the quotation-centric dataset is used, as only phase E has correctly represented non-ASCII characters. For more details regarding the phases see the datasets GitHub repository.
- Wikidata speakers This file contains the metadata of about 9 million speakers in the Quotebank dataset. The attributes provided (and the number of speakers they are available for) are date of birth (?), gender (98%), occupation (96%) nationality (84%), religion (11%), ethnic group (7%), etc.
- Wordnet Wordnet is a lexical database of the English language organized in a tree-manner. We used it to calculate the semantic distances between all the occupations in the Wikidata-dataset to a set of top 8 occupations, to avoid the curse of dimensionality when clustering with K-means.
Methods
- K-means clustering algorithm The speakers' dataset that we want to cluster to find personas in the data has only numerical features. Thus, we chose to cluster the data using the K-means clustering algorithm implemented in sklearn. To avoid the curse of dimensionality when clustering, we reduced the genders to only [male, female, others] before one-hot encoding, and also, we reduced the roughly 2400 different occupations to the semantic differences to a set of pre-defined 8 occupations. For implementation details, see the Jupyter notebook clustering.ipynb in the GitHub repository.
- Supervised learning for person score We wanted to give readers a feeling of who gets quoted a lot in the media, therefore we created a tool that lets the reader input the features of an arbitrary person, what the person talks about, and how the person talks about it. The tool then gives an estimation of how likely this person is to get quoted. The tool is based on a neural network that is trained on features of speakers in the quotebank dataset, with the label being how many times the speaker was quoted. For the implementation details, see the Jupyter notebook n_quotes_prediction.ipynb in the GitHub repository.
- Sentimental analysis The used emotion classification method is the zero-shot classification using the Hugging-Face framework that is also used in the topic classification part of the project. This method is easily scalable as 100,000 quotes were classified in less than 10 minutes, and seem to yield acceptable results. The emotion categories chosen were angry, joy, sad, fear, calm and neutral, according to the Russel model of emotion 3. For the implementation details, see the Jupyter notebook find_emotions.ipynb in the GitHub repository.
- Topic detection The approach used is called zero-shot text classification. We will be using the following fine-tuned model, appropriate for the task of zero-shot text classification: DistilBERT base model uncased. This model is fine-tuned on Multi-Genre Natural Language Inference (MNLI) dataset for the zero-shot classification task. For the implementation details, see the Jupyter notebook what.ipynb in the GitHub repository.